An Introduction to Reinforcement Learning
Reinforcement Learning is a learning method that optimizes the execution of actions in an environment based on its observable state information to maximize the reward returned from the environment. Usually, this task has to be accomplished - tabula rasa - without prior knowledge about the environment.
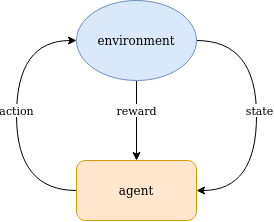 Reinforcement Learning Base Diagram
Reinforcement Learning Base Diagram
Actions are executed by a reinforcement learning agent exploiting the already collected experience but also exploring the environment searching for possibilities to maximize the collected reward.
The optimal balance between exploitation and exploration is a basic problem in reinforcement learning. That means to leverage valuable knowledge and in parallel allow to discover unknown territory that may lead to improved behavior in the sense of larger reward to be collected.
Reinforcement Learning - The Book (MIT Press, Cambridge)
An Introduction to Deep Reinforcement Learning (McGill University)
Spinning Up in Deep Reinforcement Learning (OpenAI)
The Markov Decision Process (MDP)
The Markov property
- all information about the environment is available through its observable state
- position, velocity, acceleration, etc.
- there is no hidden influence from the past to the future behavior of the environment, meaning the environment does not have a memory state that is excluded from its observable state
- the future behavior of the environment only depends on its current state and the actions executed in it
- a process with these properties is called a Markov Decision Process
Reinforcement Learning Structures
The model-free Reinforcement Learning structure consists of an agent executing the current policy, the environment, to which the agent actions are applied, and a reward function, which creates a reward signal depending on the environment state. In some cases the reward function is part of the environment, though in most real-world applications it’s a functions that transforms sensory information into a reward signal.
The environment state together with the executed action, the resulting reward, and the next state of the environment are usually used to optimize the policy. This dependency is indicated by the dashed arrows in the figure below.
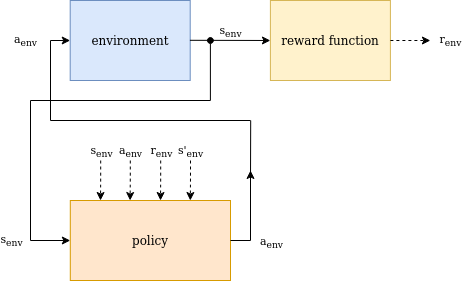 Model-Free Reinforcement Learning Structure
Model-Free Reinforcement Learning Structure
The model-based Reinforcement Learning structure includes the same elements as its model-free variant, but is extended by an environment model, which in most cases is implemented as a state model and a reward model.
In addition to data-points sampled from the environment, the environment model is used to optimize the policy by planning. This means, that the planning mechanism uses random chosen state values and the related actions generated by the current policy to query the state and reward models to generate planning data-points, which are used to optimize the policy.
The state and reward model itself are trained by sampled environment data-points. The policy and model training dependencies are indicated by dashed arrows in the figure below.
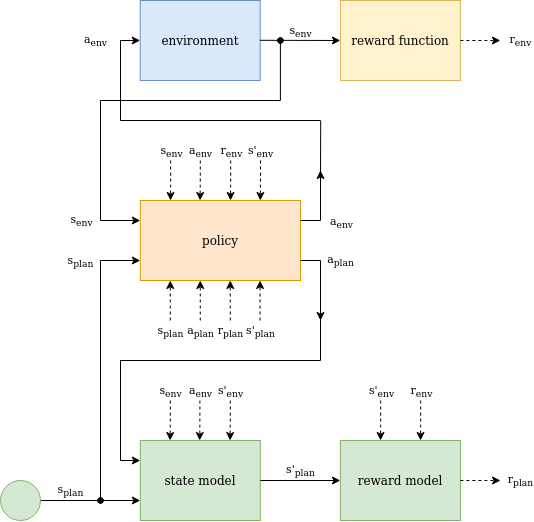 Model-Based Reinforcement Learning Structure
Model-Based Reinforcement Learning Structure
The policy and environment model can be implemented in very different ways. The most simple policy and model implementations are lookup tables, which are limited to Reinforcement Learning problems with small and discrete state and action spaces.
For problems with larger state and action spaces, neural networks can be used to implement the policy and model functions, which have the advantage to generalize and interpolate for previously unseen input data.
Depending on the type of environment the policy and/or environment model implementation may be either deterministic or stochastic, which implies different architectures and RL algorithms to be used.
Reinforcement Learning Algorithms
Temporal Difference (TD) Learning
- The Bellman Equation
- Q-Learning Algorithm (model-free)
- SARSA Algorithm (model-free)
- Expected SARSA Algorithm (model-free)
- Dyna-Q Algorithm (model-based)
Deep Q Network (DQN) Architectures
Monte Carlo Tree Search Algorithms
- The Alpha Zero Algorithm
 Alexander Amini - Reinforcement Learning, MIT 6.S191 (2020)
Alexander Amini - Reinforcement Learning, MIT 6.S191 (2020)
 Joelle Pineau - The Basics of Reinforcement Learning, McGill University (2017)
Joelle Pineau - The Basics of Reinforcement Learning, McGill University (2017)
 Serena Yeung - Deep Reinforcement Learning, Stanford University (2017)
Serena Yeung - Deep Reinforcement Learning, Stanford University (2017)
 Martin Görner - TensorFlow and Deep Reinforcement Learning (2018)
Martin Görner - TensorFlow and Deep Reinforcement Learning (2018)
 DeepMind & UCL - Reinforcement Learning Course (2018)
DeepMind & UCL - Reinforcement Learning Course (2018)
Glossary and Future Page Extensions
- environment
- deterministic state change
- stochastic state change
- deterministic reward
- stochastic reward
- environment dynamics
- branching factor
- number of possible actions in a given state
- agent
- state
- observation of the environment, sometimes also called node e.g. in MCTS
- reward
- a reward or penalty signal returned by the environment associated with the state and action chosen by the agent
- reward is usually a sparse signal and may be delayed relative to the triggering agent action(s)
- action
- an action executed in the environment resulting in a state change, sometimes in combination with a reward signal
- model-free algorithms
- model-based algorithms
- experience replay buffer
- buffer of experience data used for learning based on batch sampling
- increases sample efficiency by using buffer entries more than once during neural network training
- using sampled batches of training data from the replay buffer results in more stable training than directly using potentially correlated sequential observations
- prioritized replay for faster learning
- state
- state value function V(s)
- state-action value function Q(s, a)
- advantage function A(s, a)
- policy
- maps a state to an action or a vector of action probabilities: \(\pi(s) = a\)
- deterministic policy
- stochastic policy
- greedy policy
- a deterministic exploitation policy without any portion of random exploration
- epsilon-greedy policy
- a mostly deterministic exploitation policy with a usually small portion of random exploration
- on-policy
- if the data used for learning is generated following the current policy
- off-policy
- if the data used for learning is generated by a policy that differs from the current behavior policy
- if the data is generated using a slightly different policy, e.g. Q learning uses a greedy policy in the next state to generate learning data while following an epsilon-greedy behavior policy
- if the data is put into an experience buffer that is then used by the learning process for sampling random batches
- if two networks are used to disentangle behavior and target policy
- if the data used for learning is generated by a policy that differs from the current behavior policy
- policy evaluation
- update of state values or state-action values given a fixed policy, usually until all values converge and do not change anymore
- policy improvement
- policy update based on state values or state-action values
- (general) policy iteration
- process of interaction between policy evaluation and policy improvement
- optimistic initial values
- enforces environment exploration until all values have converged to their smaller optimal values keeping only the policy based portion of exploration
- in contrast pessimistic initial values suppress exploration and the only source of exploration may be the random action selection based on the policy
- how to learn a policy
- learn policy directly
- learn state action values and infer policy
- learn environment model and infer policy by planning
- objective function
- a reward function that can be optimized to maximize the expected discounted future reward
- discount factor
- determines the effect of future reward values depending on their distance from a state
- a parameter usually chosen between 0.95 and 1.00
- the closer to 1, the higher the impact of distant reward values
- model
- a representation of the environment that enables planning
Miscellaneous Topics
- A Beginner’s Guide to Deep Reinforcement Learning (A.I. Wiki)
- actor critic
- async advantage actor critic (A3C)
- Learning values across many orders of magnitude “adaptive normalization”
- A Distributional Perspective on Reinforcement Learning
- Recurrent DQN