Autoencoder
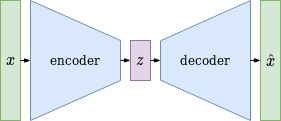 Autoencoder Structure
Autoencoder Structure
An autoencoder is a structure that encodes a high dimensional input dataset into a low dimensional - bottleneck - latent space representation from which a decoder is used to reconstruct the original input data. The idea behind this structure is to find the main underlying features of a dataset that represent its characteristics and may show up as latent space features. Both the encoder and decoder can be implemented using neural networks that learn a latent space representation by optimizing the reconstruction error of data passed through this structure. The post by Joseph Rocca perfectly shows, that even a 1-dimensional latent space can represent each complex dataset by heavily overfitting it. A classical autoencoder is trained without any mechanism of latent space regularisation and after training the decoder can most probably not be used without unexpected effects to generate new output data from latent space vectors which the decoder has not seen before during training. Thats the point where Variational Autoencoders (VAEs) come into play …
Autoencoder Implementation
import numpy_neural_network as npnn
import npnn_datasets
model = npnn.Sequential()
model.layers = [
npnn.Conv2D(shape_in=(3, 3, 1), shape_out=(2, 2, 6), kernel_size=2, stride=1),
npnn.Tanh(2 * 2 * 6),
npnn.Conv2D(shape_in=(2, 2, 6), shape_out=(1, 1, 2), kernel_size=2, stride=1),
npnn.Tanh(1 * 1 * 2),
npnn.UpConv2D(shape_in=(1, 1, 2), shape_out=(2, 2, 6), kernel_size=2, stride=1),
npnn.Tanh(2 * 2 * 6),
npnn.UpConv2D(shape_in=(2, 2, 6), shape_out=(3, 3, 1), kernel_size=2, stride=1),
npnn.Tanh(3 * 3 * 1)
]
loss_layer = npnn.loss_layer.RMSLoss(shape_in=(3, 3, 1))
optimizer = npnn.optimizer.Adam(alpha=1e-2)
dataset = npnn_datasets.FourSmallImages()
optimizer.norm = dataset.norm
optimizer.model = model
optimizer.model.chain = loss_layer
Autoencoder without Latent Space Regularization (Tanh activation)
import numpy_neural_network as npnn
import npnn_datasets
model = npnn.Sequential()
model.layers = [
npnn.Conv2D(shape_in=(3, 3, 1), shape_out=(2, 2, 6), kernel_size=2, stride=1),
npnn.LeakyReLU(2 * 2 * 6),
npnn.Conv2D(shape_in=(2, 2, 6), shape_out=(1, 1, 2), kernel_size=2, stride=1),
npnn.LeakyReLU(1 * 1 * 2),
npnn.UpConv2D(shape_in=(1, 1, 2), shape_out=(2, 2, 6), kernel_size=2, stride=1),
npnn.LeakyReLU(2 * 2 * 6),
npnn.UpConv2D(shape_in=(2, 2, 6), shape_out=(3, 3, 1), kernel_size=2, stride=1),
npnn.LeakyReLU(3 * 3 * 1)
]
loss_layer = npnn.loss_layer.RMSLoss(shape_in=(3, 3, 1))
optimizer = npnn.optimizer.Adam(alpha=1e-2)
dataset = npnn_datasets.FourSmallImages()
optimizer.norm = dataset.norm
optimizer.model = model
optimizer.model.chain = loss_layer
Autoencoder without Latent Space Regularization (LeakyReLU activation)